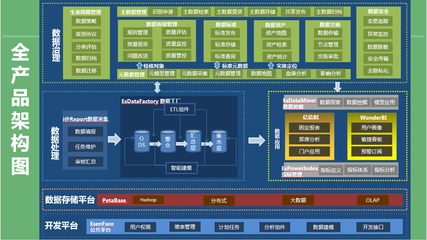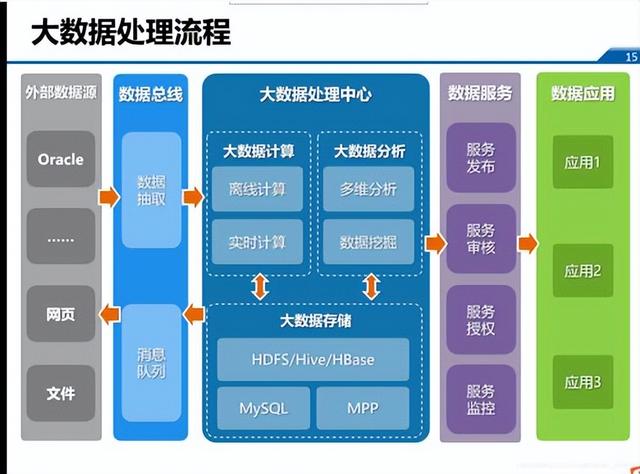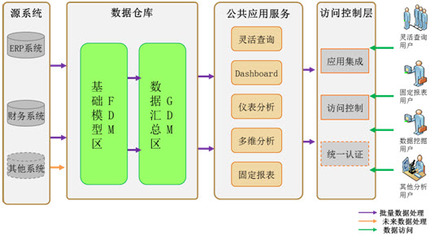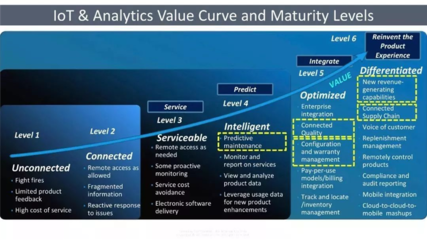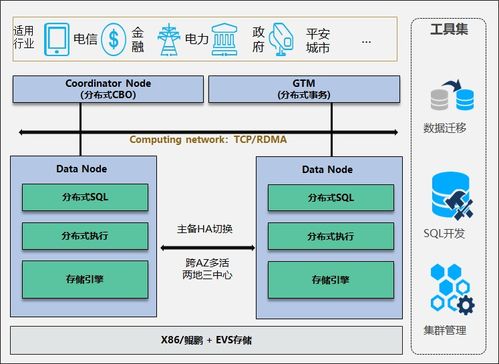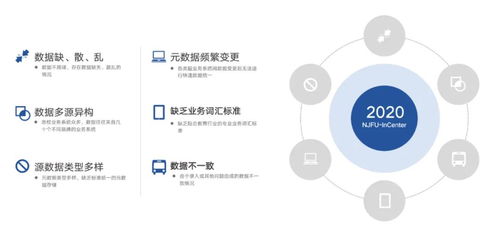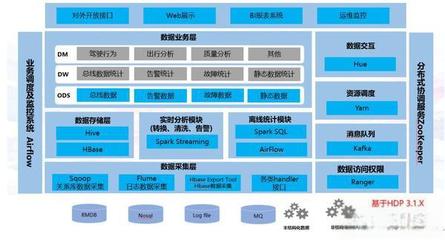
隨著車聯網產業的快速發展,中臺架構已成為支撐海量車端數據高效處理與分析的核心。數據處理服務作為車聯網中臺的關鍵組件,其架構設計的優劣直接決定了數據價值挖掘的深度與業務響應的敏捷性。本文將對市場上六款主流的車聯網中臺數據處理服務架構產品進行對比分析,旨在為技術選型與架構設計提供參考。
一、 核心架構理念對比
- 產品A(云原生一體化平臺):強調全棧云原生,基于Kubernetes容器化編排,實現數據處理微服務化。其優勢在于彈性伸縮與高可用性,但技術棧較為復雜,對運維要求高。
- 產品B(流批一體數據湖倉):以數據湖倉為核心,統一存儲原始數據與處理后的結構化數據,支持流式與批處理一體化。優勢在于數據治理與歷史回溯能力強,實時性略遜于純流處理架構。
- 產品C(邊緣-云協同計算):采用分層架構,在車端/路側邊緣節點進行初步過濾與聚合,云端進行復雜分析與建模。優勢在于降低帶寬成本、提升實時響應,但邊緣節點管理是一大挑戰。
- 產品D(領域驅動智能管道):以業務領域(如駕駛行為、電池健康)為核心組織數據處理流水線,內置豐富的領域模型與算法。優勢在于業務貼合度高、開箱即用,但跨領域擴展靈活性一般。
- 產品E(低代碼可視化編排平臺):提供圖形化界面,通過拖拽方式配置數據源、處理規則與輸出目標。優勢在于降低開發門檻、提升配置效率,但處理復雜邏輯的能力有限。
- 產品F(開源生態集成方案):基于Apache Flink、Kafka等開源組件進行集成與封裝,提供標準化數據管道。優勢在于技術開放、成本可控,但需要較強的自主研發與集成能力。
二、 關鍵能力維度分析
- 吞吐量與實時性:產品A與產品F在吞吐量與毫秒級延遲方面表現優異,尤其適合高并發實時場景(如實時預警)。產品B在批處理任務上更具優勢,產品C的實時性依賴于邊緣算力。
- 數據治理與質量:產品B與產品D在數據血緣追溯、質量監控與主數據管理方面功能完善。產品E與產品F在此方面通常需要額外開發或集成。
- 算法與智能集成:產品D內置算法最豐富,產品A與產品C通常提供標準的機器學習框架集成接口。產品E可能通過插件市場提供算法組件。
- 部署與運維成本:產品A(云原生)與產品F(開源)的運維復雜度最高,但云原生的彈性可能降低長期資源成本。產品E與產品D作為商業化產品,通常提供更完善的運維支持,但采購成本較高。產品C涉及邊緣硬件,總體擁有成本需綜合評估。
- 生態兼容性與開放性:產品F開放性最強,產品A、B、C通常對主流云服務與數據源兼容性好。產品D和E可能在特定云或數據格式上存在綁定。
三、 選型建議與
選擇車聯網中臺數據處理服務架構產品,需緊密圍繞業務場景與技術戰略:
- 追求極致實時與彈性擴展:可重點考察云原生一體化平臺(產品A)或成熟的開源集成方案(產品F)。
- 數據資產沉淀與深度分析優先:流批一體數據湖倉(產品B)或領域驅動智能管道(產品D)是更優選擇。
- 存在海量邊緣數據與帶寬約束:邊緣-云協同架構(產品C)的價值凸顯。
- 追求快速上線與降低開發投入:低代碼可視化平臺(產品E)能顯著提升初期效率。
沒有一種架構能適用所有場景。企業應結合自身數據規模、實時性要求、團隊技術棧及長期數據戰略,進行綜合評估與取舍。隨著算力網絡與AI大模型技術的發展,車聯網數據處理服務將向更智能、更自適應、云邊端深度融合的方向持續演進。